| Configuring the rrt.cfg File | ||
|---|---|---|
 | Chapter 2. Setup |  |
| Configuring the rrt.cfg File | ||
|---|---|---|
| | Chapter 2. Setup | |
The configuration file is used to specify one’s unique
environment. One can setup email addresses, report formatting, search
parameters, and environment info. Provided with the RRT tool is an
example configuration file. It resides in the rrt/lib directory. One can
copy this file for modification, or update the one provided directly. If
a copy is made, be sure to use the -config file option
when calling the tool. The following sections detail the options that
can be controlled.
The following is a list of all the parameters available for configuring email notifications:
The mail program to use for email notifications. Valid entries are:
sendmail
qmail
smtp
If sendmail or qmail
is desired, set the parameter
email_program to just the name of the
tool, e.g. sendmail. If smtp is desired then
set the variable email_program to smtp.
Also, for smtp to work the parameter
email_smtp_server must be set to the
domain name that the server lives on. The script
test_email is provided to test the different
options in order to find one that works. It has a help splash
screen available with the -help option.
Domain where the smtp server lives on, e.g.
mail.usgov.gov. This must be set if the selected
email_program is smtp. This parameter is
ignored if anything other than smtp is set.
This parameter is provide as a way to append a domain name to addresses that do not have one. This typically occurs when one is using a username as the address to send to. The domain will only be appended to addresses that do not already have one.
When using the email notification feature, one can specify
who will be sent a message by maintaining a list of addresses in
the configuration file. The keyword
email_addresses is used to designate that
a list of addresses is to follow. Each entry should be separated
by a “,”. The last entry in the list should end with a “;”.
Spaces and line feeds are ignored. There should be only one
instance of email_addresses. If there is
more than one, the last one will be the list of addresses
used.
Example 2.1. Specifying Email Addresses in Configuration File
email_addresses George.Washington@usgov.gov,
Abe.Lincoln@usgov.gov,
John.Kennedy@usgov.gov,
RichardNixon@usgov.gov;
A configuration file parameter is provided that allows one to specify what file extensions are being used to designate a test log file. This is a comma separated list where all the items must be contained on a single line. Note, extensions are not limited to just file types. One can specify a full and partial file names as well.
Example 2.2. Specifying Log File Extensions to Search and Parse
log_file_extensions .log, .txt, sylver.log, _compile.log
As of version 1.11.0 rrt is capable of parsing log files that have been compressed using the gzip tool. This is to support those verification environments that automatically compress their regression log files. Rrt will properly parse files that end in “.gz” and will store them in the rrt_logs directory. The files are stored uncompressed because web servers do not always automatically extract the files properly for viewing. When using the rrt_max_file_size parameter, it should be noted that the size of the file when it is uncompressed is the value that is used to determine if the file is too large.
The following parameters in the configuration file are used to designate such things as where the web pages, test logs, and reports are stored:
This is the top level directory where the web pages, reports, and test logs will be stored.
Name of the web home page file. This can be any web page. A template web page is provided (rrt_home.htm). The key is to have the following three lines placed in the HTML file. The results will be placed between these lines.
<!-- Regression Results Header --><PRE>
<!-- Regression Results Start -->
<!-- Regression Results End --></PRE>
Name of the archive web page. This is the page that regression results are moved to before deletion. The individual report pages are available. However, the links to the each of the log files is disabled. A template web page is provided (rrt_archived.htm).
This is the link string that one would enter into the
browser to access the web pages minus the
master_web_page name.
Location where test log files will be stored. This is a
path that will be placed under the
master_web_dir location. Therefore, if
the storage area needs to be located elsewhere, then use a
symbolic link to the desired destination.
Location where report files will be stored. The same restriction applies to this directory as specified in the log_archive_path parameter.
There are two methods that one can use to store and access the web pages. One is through a web server. The other is to directly point to the web home page file directly. In the first method every individual who wishes to access the information does not have to know or have access to the file system, just the web server. In direct file mode, each person who wants to access the results must be able to read from the directory location that the files are maintained.
If one is working on a system that has an Apache web server one
can just copy the directory “rrt/public_html” to “~/”. Then, the web
pages can be accessed via the link
http://<host>/~<user>/<rrt_home_page>.
If one is using a different web server, does not have a user account
on the web server machine, or just does not wish to use their personal
home directory, then one will have to talk to the web administrator to
set up a link.
Rrt provides several parameters to reduce the time it takes to search for, parse, and store log files. The following can be defined in the configuration file.
Parameter that allows one to set the parsing mode that RRT uses when parsing a file. The default is to parse the entire log file. However, the more search keys one has the longer it takes for RRT to parse the file. Since in 95% (or higher) of the time the information that one is parsing for is at the beginning and end of the log file, parsing the middle of large files is needless. Therefore, the following fast mode allows one to tell RRT to only look at the top x bytes of the file as well as only the last x bytes of the file. If you need to parse the entire file then comment out the line, or set the value to 0.
Occasionally, in a verification environment a test will get into a mode where the simulation only ends after a watchdog timeout. This can result in an output log file that exceeds 1 Gigabyte or more. These files can be time consuming to parse and they can also use up much needed disk space because rrt will store them for access via the web interface. The rrt_max_file_size parameter will set a maximum limit that rrt will use to parse and store a file. If a file exceeds this limit, rrt will only parse and store the upper rrt_max_file_size / 2 bytes of the file. It will also parse and store the lower rrt_max_file_size / 2 portion of the file. The middle portion of the file will not be parsed and will be discarded. The parameter is specified in number of Megabytes. The default is 20 MBytes
If the rrt_fast_mode parameter is defined then it determines the amount of the file that is parsed regardless if the file is too large. However, the storage rule will still apply.
This is a comma separated list of directory names to include in the search for log files. The directory names do not need to be complete. The search will match partial names. For example, if all log files are stored in run_<seed> directories then set the include value to be run_. The result will be only those paths that have “run_” in their name will be searched. This parameter only applies when using the rrt –recursive command line option.
include_dir_types run_
This parameter allows one to define a comma separated list of directory names to exclude from the search for log files. If the name appears anywhere in the path it is excluded. Note, Exclusion has precedence over inclusion using the include_dir_types parameter. This parameter only applies when using the rrt -recursive command line option.
exclude_dir_types work, src
The rrt -archive and
-delete_archive option commands are based on
the date the regressions were parsed. As a project matures,
regressions may stop or only be run occasionally. If a cron
process has been setup and it has not been disabled the result
would be that when someone comes back to review the regression
results, everything is gone because the date thresholds were
met.
The rrt_num_not_to_archive
parameter allows one to specify a minimum number of regressions
to be kept on the master web page regardless of their
date-stamp. These reports will be maintained on the main page
and all of the log files will still be accessible. Default:
10
This parameter specifies the number of reports to maintain on the archive web page regardless of their date-stamp. Only the reports themselves will be maintained. Any archived log files will still be removed. Default: 20
Special parameters are provided that can be used to format the output information that is displayed on each of the web pages. The following parameters are used in the configuration file to define the action that is to be performed on the variable that comes after.
Assigns to a defined or user specified variable the pearl search string to use to capture data. This is the method in which way one details what information one would like to retrieve from each of the test result files. The variables defined here are then used to populate the master & report fields. See Section : Predefined Variables for a list of predefined variable names.
Designates the title, content, width, and justification of a column field on the master/home web page. See the below report field example for the format.
Designates the title, content, width, and justification of a column field in the report files.
Example 2.3. Setting Up Search Keys
The following shows the assigning of Perl regular expressions to variable names. Note how these variables are used in the next example to set up the report fields.
search_key test_name_string "/testfn=(\w+)/"
search_key passed_string "/(PASSED)/"
search_key failed_string "/(FAILED)/"
The above variables are rrt defined and are the minimum set that need search definitions in order for the tool to work properly. Any other search key variables are considered user defined and can be anything the end user wishes. Also, if the “test_name_string” is not matched in the log file then the log file is considered invalid and is removed from the report. This is to account for those environments that may have .log files that are generated by different tools (See Section : Predefined Variables for a list of predefined variables).
Example 2.4. Main Web Page Report Set-Up
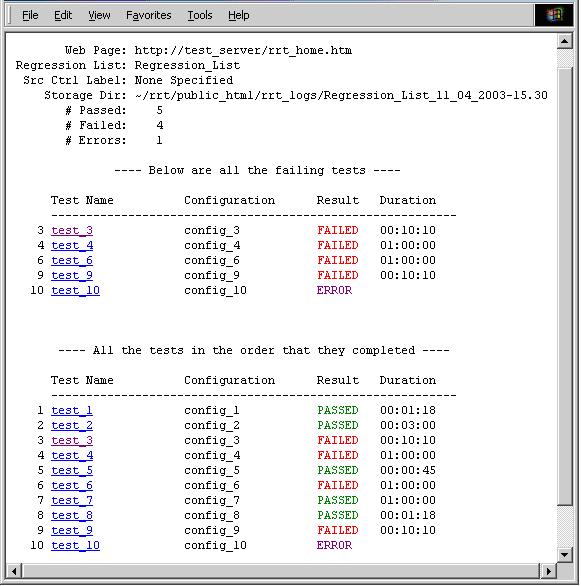
Setting up the master fields. This is an example of how to set up the configuration file to display tabulated regression results data on the main web page. See Figure 1.1, “Main Report Web Page” for the subsequent output.
| Field Type | Keyword | Column Header | Col | Width | Justification (L/R/C) |
| master_field | date_stamp | "Time Stamp" | 1 | 16 | C |
| master_field | list_name | "Regression List" | 2 | 24 | L |
| master_field | pass_total | "Passed" | 3 | 6 | R |
| master_field | fail_total | "Failed" | 4 | 6 | R |
| master_field | error_total | "Errors" | 5 | 6 | R |
| master_field | test_total | "Total" | 6 | 5 | R |
Example 2.5. Test Report Set-Up
Setting up the report fields. This is an example of how to set up the information that will be displayed on the individual test results page. See Figure 2.1: Regression Report Web Page for the resultant output.
| Field Type | Keyword | Col | Column Header | Min Width | Justification (L/R/C) |
| report_field | test_name_string | 1 | "Test name" | 16 | L |
| report_field | user_defined_1 | 2 | "Configuration" | 16 | L |
| report_field | passed_string | 3 | "Result" | 6 | L |
| report_field | failed_string | 3 | "Result" | 6 | L |
| report_field | error_string | 3 | "Result" | 6 | L |
| report_field | test_duration | 4 | "Duration" | 8 | R |
In the above example, the passed_string,
failed_string, and
error_string variables share a common column
number. This overloading works because only one should be true for
any given test.
RRT has a set of variables that are available for use in the
output reports. The test_name,
passed_string, and failed_string
must be set in the configuration file by the user for the tool to work
properly. The remaining variables are controlled by RRT and contain
information relevant to the regression.
This variable is set for each log file that has a Perl regular expression match using the “search_key” mechanism. It is provided as a means of capturing the name of the test that results are being retrieved for. If no test name is matched then the log file is removed from the report. This is to account for those environments that may have .log files that are generated by different tools. For each match the test_total counter is incremented. This variable is typically used in the report_fields reports (Figure 2.1: Regression Report Web Page). It is suggested that the test name be located at the start of the log file. That way if the test errors out due to compile or system issues, RRT will not delete the log file because it could not find a test name
This variable is set for each log file that has a Perl regular expression match using the “search_key” mechanism. It is provided as a way of determining whether a test ran to completion and “PASSED”. For each test that passes, the pass_total counter is incremented. This variable is typically used in the report_fields reports (Figure 2.1: Regression Report Web Page).
This variable is set for each log file that has a Perl regular expression match using the “search_key” mechanism. It is provided as a way of determining whether a test ran to completion and “FAILED”. For each test failure the fail_total counter is incremented. This variable is typically used in the report_fields reports (Figure 2.1: Regression Report Web Page).
This string has the constant value of “ERROR”. It cannot be set via the search_key mechanism. It represents the failure case where a test_name string was found but no pass/fail string was matched. This provides a means of categorizing tests that did not run to completion, e.g. Compilation errors, segmentation faults, etc. Each time no pass/fail info is found in a log file the error_total counter is incremented. This variable is typically used in the report_fields reports (Figure 2.1: Regression Report Web Page).
If not set from the command line this variable represents the time that the RRT tool was called to perform its task. The default format is MM_DD_YYYY-hh.mm. It is typically used on the master report page (Figure 1.1: Main Report Web Page).
Represents the name of the list of tests that were run. It is set from the command line. The default is “Regression_list”. It is typically used on the master report page (Figure 1.1: Main Report Web Page).
This is a counter that represents each of the passed_string matches, i.e. The tests that passed. It is typically used on the master report page (Figure 1.1: Main Report Web Page).
This is a counter that represents each of the fail_string matches, i.e. The tests that failed. It is typically used on the master report page (Figure 1.1: Main Report Web Page).
This is a counter that represents the number of log files that did not have a pass or fail match. It is typically used on the master report page (Figure 1.1: Main Report Web Page).
This is a counter that represents each of the test_name matches, i.e. The number of tests that were run. It is typically used on the master report page (Figure 1.1: Main Report Web Page).
| |  | |
| Environment Variables |  | Chapter 3. Command Line Options |